728x90
목차
- 개요
- Stream 소개
2-1. 특징
2-2. 중개 연산
2-3. 종료 연산
2-4. parallelStream
- 결론
1. 개요
Java8 부터 나온 기능 중 많은 사람들에게 관심을 가졌던 기능 중 하나이다.
자바에서는 많은 양의 데이터를 저장하기 위해 배열이나 컬렉션을 사용한다. 이렇게 저장된 데이터에 접근하기 위해서는 반복문이나 반복자(iterator)를 사용하여 매번 새로운 코드를 작성해야 한다.
이렇게 작성된 코드는 길이가 너무 길고 가독성도 떨어지며, 코드의 재사용이 거의 불가능하다.
즉, 데이터베이스의 쿼리와 같이 정형화된 처리 패턴을 가지지 못했기에 데이터마다 다른 방법으로 접근해야만 했다.
이러한 문제점을 극복하기 위해서 스트림 API를 도입하였다.
스트림 API는 데이터를 추상화해서 다루므로 다양한 방식으로 저장된 데이터를 읽고 쓰기 위한 공통된 방법을 제공한다. 따라서, 스트림 API를 이용하면 배열이나 컬렉션뿐만 아니라 파일에 저장된 데이터도 모두 같은 방법으로 다룰 수 있게 된다.
2. Stream 소개
1. 특징
- 간단히 말하면, ‘연속된 데이터를 처리하는 연산의 모음’ 이라고 말 할 수 있다.
- 스트림은 원본 데이터를 변경하지 않는다.
- 스트림은 외부 반복을 통해 작업하는 컬렉션과는 달리 내부 반복(internal iteration)을 통해 작업을 수행한다.
- 스트림은 재사용이 가능한 컬렉션과는 달리 단 한 번만 사용할 수 있다.
- 스트림의 연산은 필터(filter)-맵(map) 기반의 API를 사용하여 지연(lazy) 연산을 통해 성능을 최적화한다.
- 스트림은 parallelStream() 메서드를 통한 손쉬운 병렬 처리를 지원 한다.
- 스트림은 아래와 같이 3가지 단계를 걸쳐 동작한다.
- 스트림의 생성
- 스트림의 중개 연산 (스트림의 변환)
- 스트림의 최종 연산 (스트림의 사용)
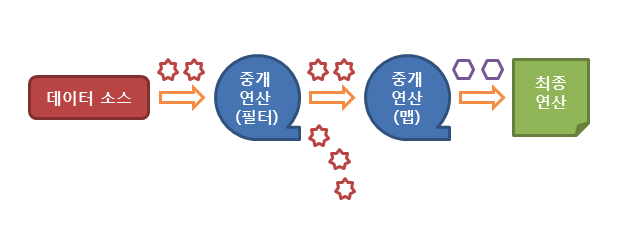
- 0 또는 다수의 중개 연산과 한개의 종료 오퍼레이션으로 구성한다.
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("kim jeong min");
list.add("Jammini");
list.add("stream");
list.add("api");
list.stream().map((s) -> {
System.out.println(s);
return s.toUpperCase();
});
}위의 코드를 실행하면 아무것도 출력하지 않는다.
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("kim jeong min");
list.add("Jammini");
list.add("stream");
list.add("api");
list.stream().map((s) -> {
System.out.println(s);
return s.toUpperCase();
}).count();
}kim jeong min
Jammini
stream
api- 즉, 스트림의 데이터 소스는 종료연산을 실행할 때만 처리된다.
2. 중개 연산
- 데이터를 가공할 때 사용되며 연산 결과로 Stream 타입을 리턴한다. 따라서 여러개의 중간 연산을 연결할 수 있다.
- stateless(독립적)
- 대부분 stateless로 행위를 실행할때 다른 요소에 대해서 독립적으로 처리 된다.
- stateful(종속적)
- 선행된 연산의 영향을 받아서 sorted, distinct 같은 중개 연산자는 종속적으로 처리 된다.
| 메소드 | 설명 |
|---|---|
| Stream<T> filter(Predicate<? super T> predicate) | 해당 스트림에서 주어진 조건(predicate)에 맞는 요소만으로 구성된 새로운 스트림을 반환함. |
| <R> Stream<R> map(Functoin<? super T, ? extends R> mapper) | 해당 스트림의 요소들을 주어진 함수에 인수로 전달하여, 그 반환값으로 이루어진 새로운 스트림을 반환함. |
| <R> Stream<R> flatMap(Functoin<? super T, ? extends Stream<? extends R>> mapper) | 해당 스트림의 요소가 배열일 경우, 배열의 각 요소를 주어진 함수에 인수로 전달하여, 그 반환값으로 이루어진 새로운 스트림을 반환함. |
| Stream<T> distinct() | 해당 스트림에서 중복된 요소가 제거된 새로운 스트림을 반환함.내부적으로 Object 클래스의 equals() 메소드를 사용함. |
| Stream<T> sorted()Stream<T> sorted(Comparator<? super T> comparator) | 해당 스트림을 주어진 비교자(comparator)를 이용하여 정렬함.비교자를 전달하지 않으면 영문사전 순(natural order)으로 정렬함. |
| Stream<T> peek(Consumer<? super T> action) | 결과 스트림으로부터 각 요소를 소모하여 추가로 명시된 동작(action)을 수행하여 새로운 스트림을 생성하여 반환함. |
| Stream<T> limit(long maxSize) | 해당 스트림에서 전달된 개수만큼의 요소만으로 이루어진 새로운 스트림을 반환함. |
| Stream<T> skip(long n) | 해당 스트림의 첫 번째 요소부터 전달된 개수만큼의 요소를 제외한 나머지 요소만으로 이루어진 새로운 스트림을 반환함. |
3. 종료 연산
- 스트림 처리를 마무리하기 위해서 사용되며, 숫자값을 리턴하거나 목록형 데이터를 리턴한다.
| 메소드 | 설명 |
|---|---|
| void forEach(Consumer<? super T> action) | 스트림의 각 요소에 대해 해당 요소를 소모하여 명시된 동작을 수행함. |
| Optional<T> reduce(BinaryOperator<T> accumulator)T reduce(T identity, BinaryOperator<T> accumulator) | 처음 두 요소를 가지고 연산을 수행한 뒤, 그 결과와 다음 요소를 가지고 또다시 연산을 수행함. 이런 식으로 해당 스트림의 모든 요소를 소모하여 연산을 수행하고, 그 결과를 반환함. |
| <R,A> R collect(Collector<? super T,A,R> collector) | 인수로 전달되는 Collectors 객체에 구현된 방법대로 스트림의 요소를 수집함. |
| Optional<T> min(Comparator<? super T> comparator) | 해당 스트림의 요소 중에서 가장 작은 값을 가지는 요소를 참조하는 Optional 객체를 반환함. |
| Optional<T> max(Comparator<? super T> comparator) | 해당 스트림의 요소 중에서 가장 큰 값을 가지는 요소를 참조하는 Optional 객체를 반환함. |
| long count() | 해당 스트림의 요소의 개수를 반환함. |
| boolean anyMatch(Predicate<? super T> predicate) | 해당 스트림의 일부 요소가 특정 조건을 만족할 경우에 true를 반환함. |
| boolean allMatch(Predicate<? super T> predicate) | 해당 스트림의 모든 요소가 특정 조건을 만족할 경우에 true를 반환함. |
| boolean noneMatch(Predicate<? super T> predicate) | 해당 스트림의 모든 요소가 특정 조건을 만족하지 않을 경우에 true를 반환함. |
| Optional<T> findFirst()Optional<T> findAny() | 해당 스트림에서 첫 번째 요소를 참조하는 Optional 객체를 반환함.(findAny() 메소드는 병렬 스트림일 때 사용함) |
| T sum() | 해당 스트림의 모든 요소에 대해 합을 구하여 반환함. |
| Optional<T> average() | 해당 스트림의 모든 요소에 대해 평균값을 구하여 반환함. |
4. parallelStream
- stream을 보다 빠르게 처리하려면 parellelStream을 사용하면 되는데, 이는 병렬로 처리하기 때문에 CPU도 많이 사용하고 몇개의 쓰레드로 처리할지가 보장되지 않는다.
- 간단히 말하면, 쓰레드를 만들면서 처리를 하면 비용이 들게 된다. 쓰레드를 만들고 수집하고 또한 쓰레드간의 컨텍스트스위치 비용 등이 기존 Stream을 사용해서 처리하는 것보다 병렬로 처리하는게 더 오래 걸릴 수도 있기 때문이다.
- 보통 데이터가 방대한 경우 parallelStream을 사용하는게 효과가 좋지만 충분한 성능 테스트를 하고 난 후 에 사용 하도록 하자.
5. 결론
- 자바8에서 나온 스트림은 ‘연속된 데이터를 처리하는 연산의 모음’이라고 정의 할 수 있다.
- 스트림은 생성 → 중개연산 → 최종연산 이렇게 3단계로 나눌 수 있다.
- 병렬 처리를 하는 parallelStream이 항상 빠르다고 보장할 수 없기에 충분한 성능 테스트를 한 후 사용해야 한다. parallelStream에 대해 자세히 알고 싶다면 이 링크(https://github.com/Jammini/TIL/blob/master/java/parallelstream.md)를 타고 더 자세히 알아보자
참고
- 자바의 신 VOL.2
반응형
'Java & Kotlin' 카테고리의 다른 글
| 자바에서 동시성 문제를 해결하기 위한 방법 (0) | 2023.04.12 |
|---|---|
| ParallelStream은 항상 Stream보다 성능이 좋을까? (0) | 2023.04.11 |
| __try-with-resources로 쉽게 자원해제하기__ (0) | 2023.04.09 |
| 자바의 IO와 (New)NIO란? (0) | 2023.04.09 |
| 자바에서 transient 는 어떤 키워드 인가? (0) | 2023.04.03 |


