728x90
목차
- 개요
- HashTable
- HashMap
- ConcurrentHashMap
4-1. 동기화처리 방식
- HashMap vs HashTable vs ConcurrentHashMap
- 결론
1. 개요
Hashtable, HashMap, ConcurrentHashMap 모두 Map 인터페이스를 구현한 컬렉션들이다.
기본적으로 key와 value구조를 가지게 되는데 서로 어떤 차이가 있는지 구현체를 비교해보자.
2. Hashtable
- (key, value) Null 허용 X
- 동기화보장 O
- Hashtable은 thread-safe하며 데이터를 다루는 메소드인 get, put, remove 등 과 같은 메소드들이 아래 코드 처럼 synchronized가 붙은 메소드로 이루어져있다. 메소드를 호출하기전에 쓰레드간 락을 걸기에 멀티쓰레드 환경에서 무결성은 보장하지만 성능상 매우 좋지 못해 잘 사용하지 않는 클래스이다.
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public synchronized V get(Object key) { ... }
public synchronized V put(K key, V value) { ... }
public synchronized V remove(Object key) { ... }
}3. HashMap
- (key, value) Null 허용 O
- 동기화보장 X
- HashMap은 thread-safe하지 않고 동기화 처리를 하지 않기 때문에 데이터를 다루는 속도가 빠르다. hashtable과 달리 신뢰성과 안정성이 떨어져 싱글 쓰레드 환경에서 사용하는게 좋다.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
public V get(Object key) { ... }
public V put(K key, V value) { ... }
public V remove(Object key) { ... }
}4. ConcurrentHashMap
- (key, value) Null 허용 X
- 동기화보장 O
- Hashtable은 성능이슈와 HashMap의 동기화 문제를 보완하기 위해 ConcurrentHashMap이 등장했다. 데이터를 다룰때 Entry를 조작하는 경우에 해당 Entry에 대해서만 락을 건다. 그래서 멀티쓰레드 환경에서의 성능을 향상시킨다.
4-1. 동기화처리 방식
- ConcurrentHashMap의 값을 집어 넣는 put동작 내부를 봐보자.
- 크게 2가지를 나누어서 살펴보면,
- 해시테이블 버킷이 비어있다면, 노드를 삽입하는 경우에, lock을 사용하지 않고 CAS알고리즘을 이용해 새로운 노드로 버킷에 삽입한다.
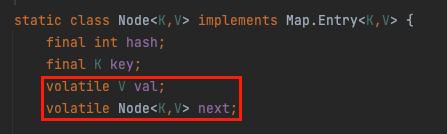
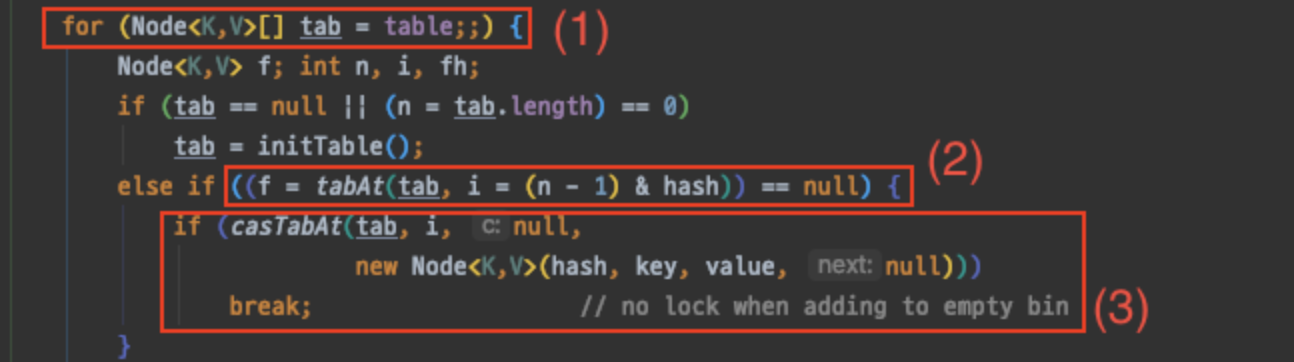
(1) 무한 루프. table 은 내부적으로 관리하는 가변 배열이다. 해당 노드를 보면 val과 다음 값을 가리키는 next에 volatile이라는 키워드를 확인 할 수 있다.
(2) 새로운 노드를 삽입하기 위해, 해당 버킷 값을 가져와(tabAt 함수) 비어 있는지 확인한다.
(3) 다시 Node 를 담고 있는 volatile 변수에 접근하여 Node 와 기대값(null) 을 비교하여(casTabAt 함수) 같으면 새로운 Node 를 생성해 넣고, 아니면 (1)번으로 돌아간다(재시도).
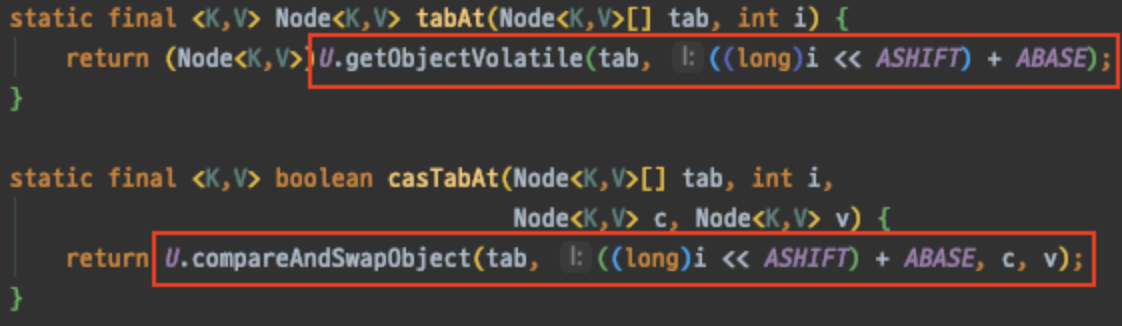
volatile변수에 2번 접근하는 동안 원자성(atomic)을 보장하기 위해 기대되는 값과 비교(Compare)하여 맞는 경우에 새로운 노드를 넣는다(Swap).
CAS 구현은 java.util.concurrent.atomic 패키지의Atomic* 클래스들과 동일하게 내부적으로 sun.misc.Unsafe을 사용하고있다. (Unsafe 는 jdk11 부터 없어 졌다고 한다.)
- 해시테이블 버킷이 비어있지 않다면, synchronized를 이용해 해당 버킷에 하나의 쓰레드만 접근할 수 있도록 락을 건다.
즉, 서로 다른 쓰레드가 같은 해시테이블내 버킷에 접근할 수 없게 된다.
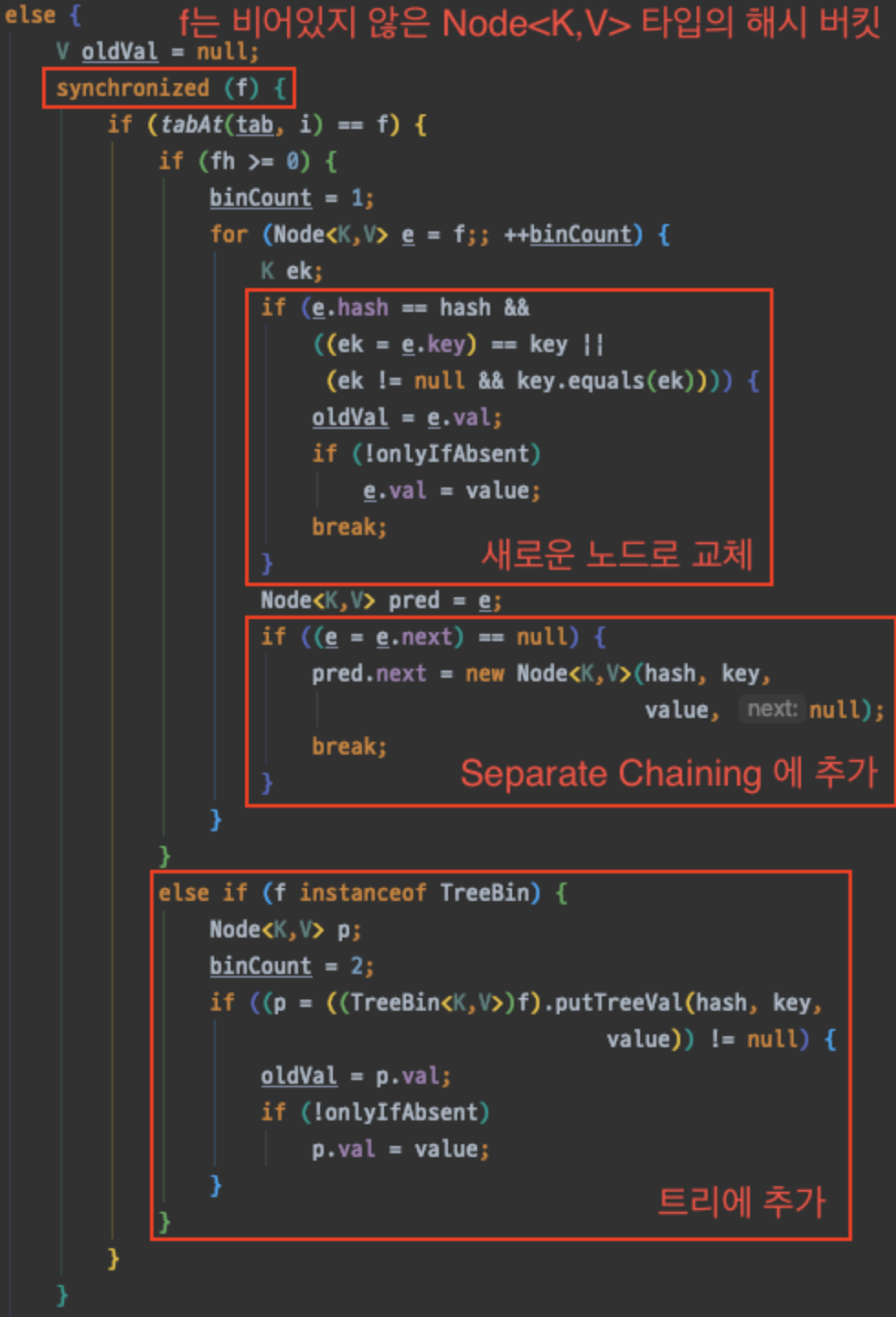
- synchronized 안의 로직은 HashMap 과 비슷한 로직이다. 동일한 Key 이면 Node 를 새로운 노드로 바꾸고, 해시 충돌(hash collision) 인 경우에는 Separate Chaining 에 추가 하거나 TreeNode 에 추가한다. TREEIFY_THRESHOLD 값에 따라 체이닝을 트리로 바꾼다.
5. HashMap vs HashTable vs ConcurrentHashMap
| HashMap | HashTable | ConcurrentHashMap | |
| Synchronized | X | 모든 연산에 Synchronized | 쓰기 연산에만 Synchronized |
| key, value Null 허용 | O | X | X |
| 언제 사용해야하나 | 싱글쓰레드 환경 | legacy클래스이므로 추천하지 않는다. | 멀티쓰레드 환경 |
6. 결론
- 위의 표처럼 간단하게 HashMap, HashTable, ConcurrentHashMap에 대한 차이를 비교하였다
- ConcurrentHashMap같은 경우는 자바에서 동시성 문제를 해결하기 위한 대표적인 키워드인 synchronized, volatile, atomic 키워드를 다 사용한 클래스이다. 이 키워드를 자세히 알고 싶다면 이 링크(https://github.com/Jammini/TIL/blob/master/java/java_ concurrency.md)로 이동해서 확인해보자
- 싱글쓰레드 환경이면 HashMap을 멀티쓰레드 환경이면 ConcurrentHashMap을 사용 하자.
참고
반응형
'Java & Kotlin' 카테고리의 다른 글
| __GC 방식에는 어떤 것들이 있을까?__ (0) | 2023.05.04 |
|---|---|
| GC**(GarbageCollection)**는 어떻게 동작하며 왜 필요할까? (0) | 2023.05.02 |
| 자바에서 동시성 문제를 해결하기 위한 방법 (0) | 2023.04.12 |
| ParallelStream은 항상 Stream보다 성능이 좋을까? (0) | 2023.04.11 |
| 자바8에 추가된 Stream에 대해 알아보자 (0) | 2023.04.10 |

